Skąd biorą się błędy 404 na stronie i jak je ogarnąć w praktyce

Błędy 404 mają różne źródła i nie da się ich sprowadzić do jednego powodu. Najprostszy przypadek to sytuacja, w której sam coś zmieniasz: usuwasz podstronę, zmieniasz adres wpisu, przenosisz treść do innej kategorii albo porządkujesz menu. Stary adres przestaje działać, ale w internecie wciąż ktoś próbuje w niego wejść.
Drugi typ problemu pojawia się wtedy, gdy kupiłeś domenę po kimś. W Google nadal krąży masa starych adresów poprzedniego właściciela. Ludzie w to klikają, trafiają na 404 i to obniża jakość strony w oczach wyszukiwarki.
Trzecia sytuacja to linki z zewnętrznych serwisów: fora, katalogi firm, stare artykuły sponsorowane, blogi. Ktoś kiedyś wkleił link do Twojej strony, ale dziś ten adres już nie istnieje. Nie poprawisz tego na tamtej stronie – możesz tylko przechwycić ruch u siebie.
Czwarty przypadek to linki wychodzące, czyli takie, które masz u siebie w treści, ale prowadzą do zasobów na cudzych stronach, które już zniknęły. To nie generuje błędów na Twojej stronie, ale psuje jakość Twoich artykułów.
W dalszej części artykułu pokazuję, jak rozpoznać, z którego źródła pochodzi dany błąd 404 i co z nim zrobić, korzystając z narzędzi dostępnych dla zwykłego właściciela strony.
Linki, które przestały działać po zmianach na stronie
To jest najprostszy i najczęstszy przypadek. Sam coś zmieniasz: usuwasz podstronę, zmieniasz adres wpisu, przenosisz treść do innej kategorii albo porządkujesz menu. Stary adres przestaje działać, ale w internecie wciąż ktoś próbuje w niego wejść z zakładek, z forów, z Google, z historii przeglądarki.
Jak to wykryć
Do tego służy wtyczka Redirection, a konkretnie jej zakładka 404s. Redirection rejestruje każde wejście na nieistniejący adres na Twojej stronie. Jeśli widzisz tam adresy, które wyglądają znajomo i pasują do Twojej obecnej struktury, to znaczy, że to są Twoje własne stare linki.
Przykłady:
/poradnik/ → zmieniłeś na /blog/poradnik/
/cennik/ → przeniosłeś do /oferta/
/kontakt.html → usunąłeś, bo masz nową stronę kontaktu
Redirection pokaże Ci dokładnie te wejścia.
Instalacja
Wtyczka w repozytorium WordPressa, darmowa. Jest kilka podobnych, ta konkretna jest pod nazwą Redirection albo Przekierowanie, autorstwa Johna Godleya.
Po włączeniu jest nietypowo, bo konfiguracja instalacji
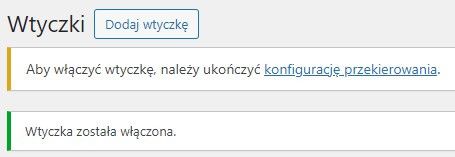
Klik prowadzi dalej:
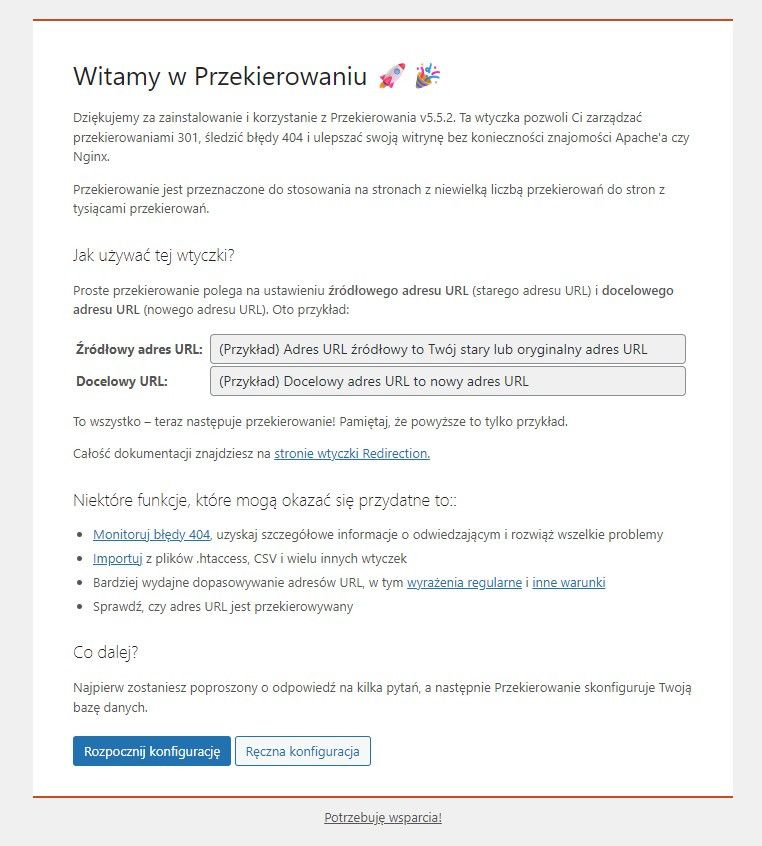
Na tym ekranie niczego nie wypełniasz. Wybierz "Ręczna konfiguracja". Na kolejnym ekranie będzie edytowalne pole, którego również nie ruszasz.
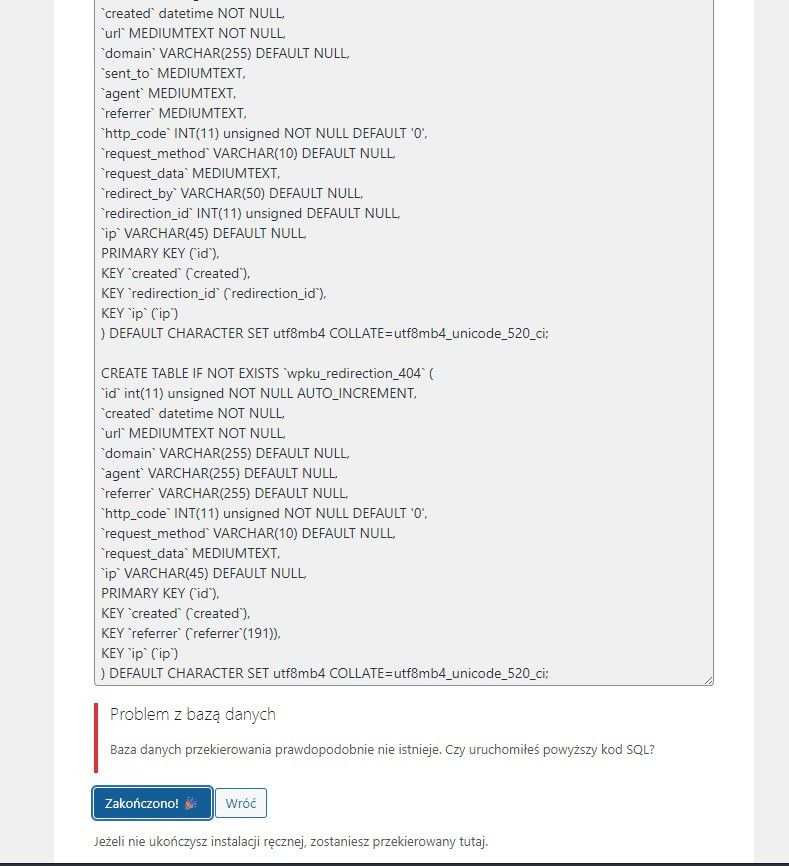
Jak widać coś się tu nie udało. Nie klikaj wtedy "Zakończono", tylko zaznacz całą zawartość okna i skopiuj do schowka.
Teraz musisz się dostać do bazy SQL. Trzeba się zalogować do swojego dostawcy hostingu.
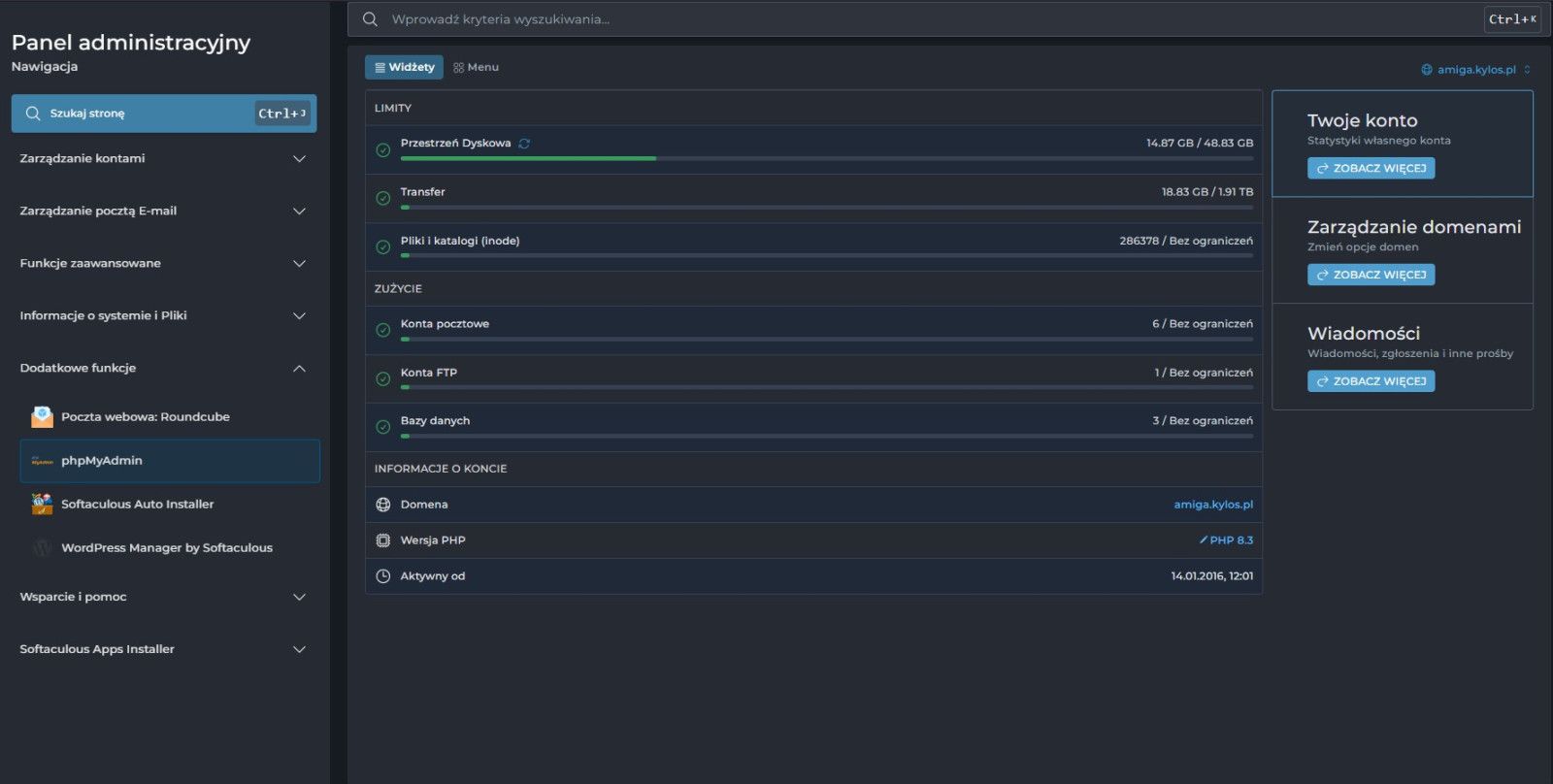
Tu Direct Admin, czyli Panel administracyjny. To może różnie wyglądać, ale poszukaj pozycji phpMyAdmin, u mnie to było w "Dodatkowych funkcjach". W nowej zakładce otworzy się widok baz danych. W lewym panelu wybierz z listy bazę powiązaną ze swoją stroną, co powoduje załadowanie się widoku w głównym ekranie.
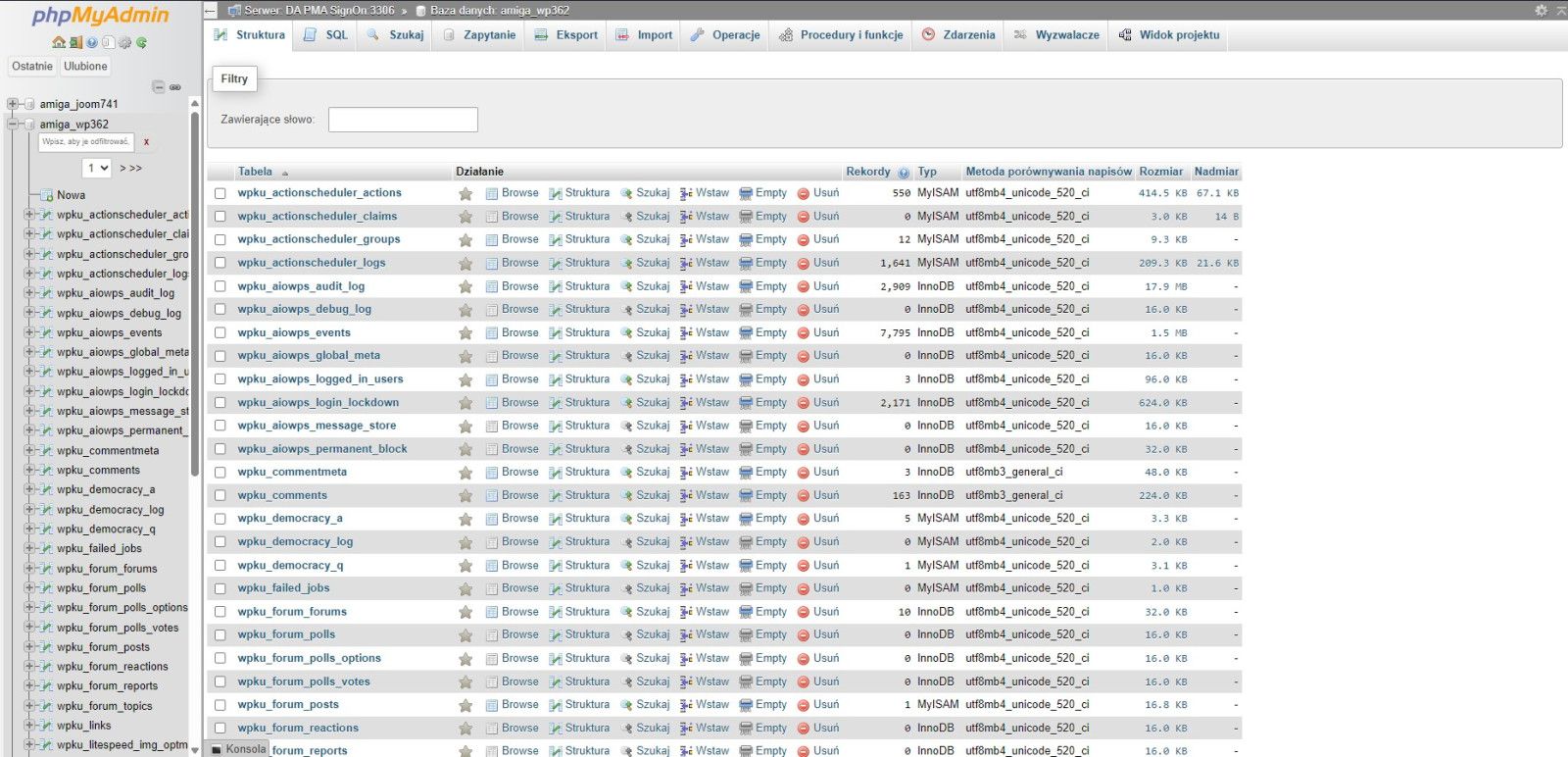
Następnie z górnego paska wybierz zakładkę SQL co otworzy okno zapytań do bazy.
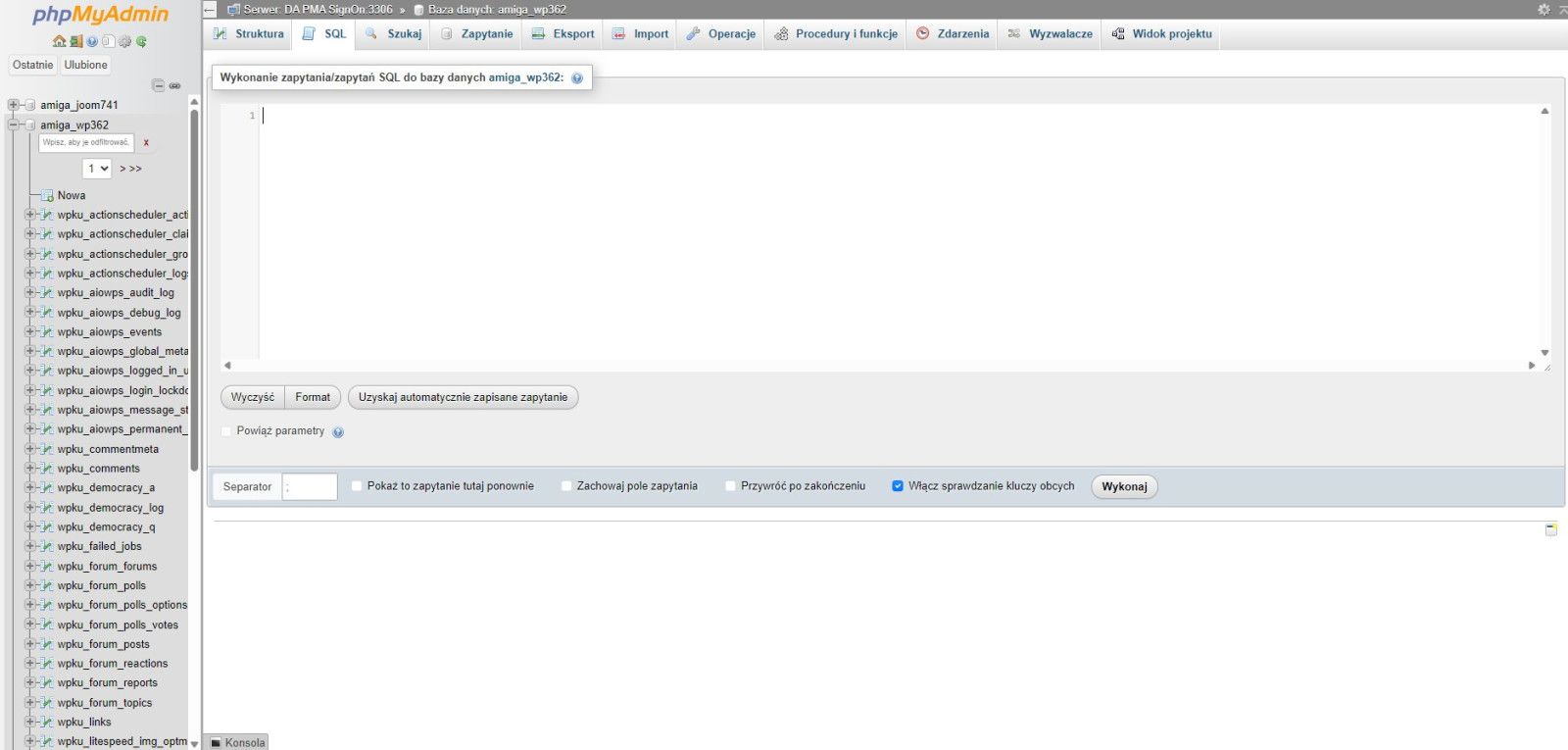
W to okno wklejasz zawartość ze schowka. przewijasz w dół strony i klikasz "Wyślij".
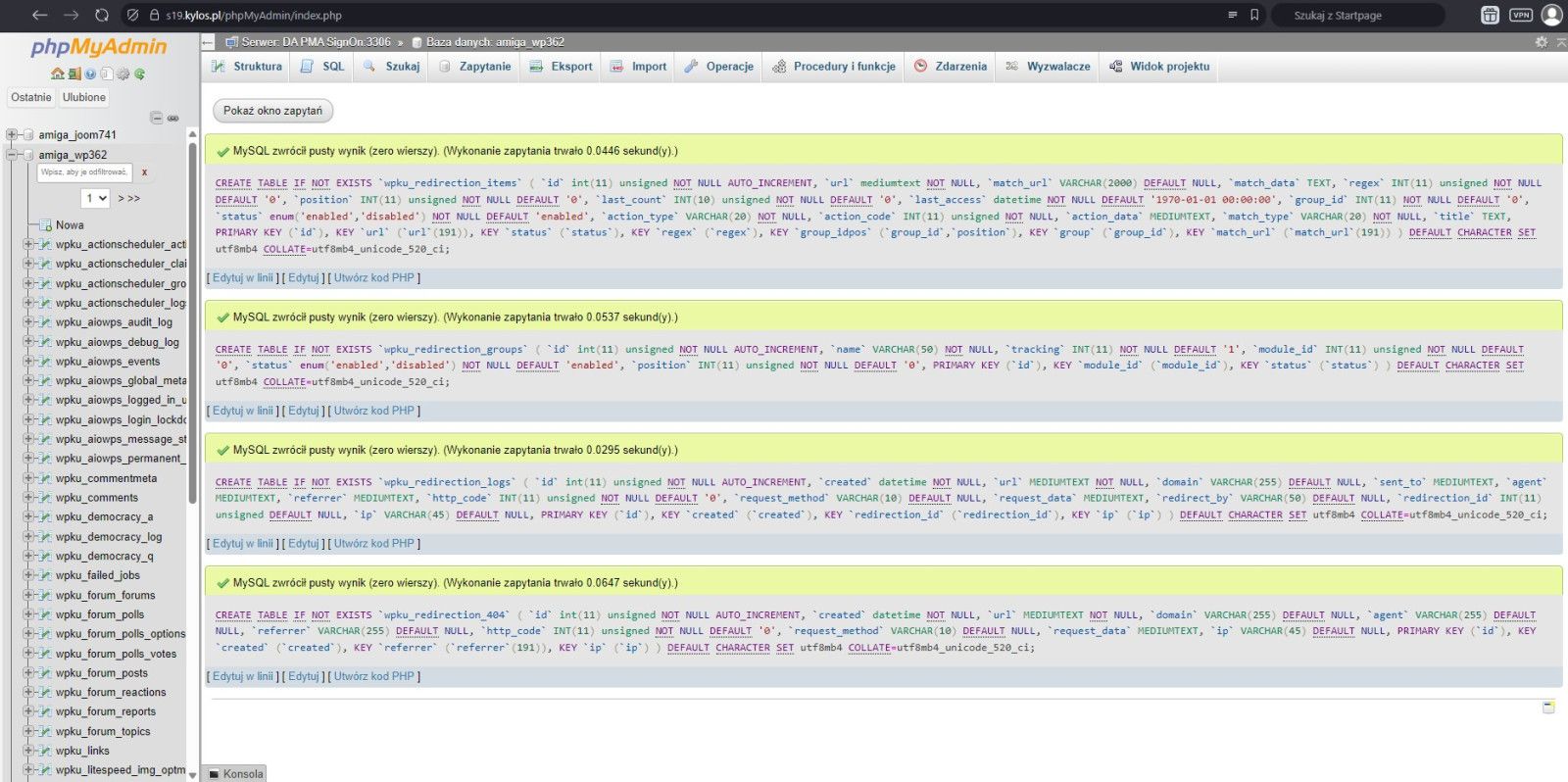
Taki widok ("na zielono") oznacza, że wszystko przebiegło prawidłowo.
Teraz wracasz do strony w panelu WordPressa, gdzie utknęliśmy i stamtąd przeklejaliśmy. Odśwież ją, po prostu klawiszem F5.
Właśnie zainstalowaliśmy wtyczkę do przekierowań. Będzie widoczna w panelu WordPressa w zakładce Narzędzia pod nazwą Redirection.
Redirection nie odróżnia ludzi od botów. Dlatego lista 404 szybko robi się zaśmiecona i trzeba umieć odróżnić realne problemy od szumu technicznego.
Jak rozróżnić śmieci po botach od prawdziwych błędów
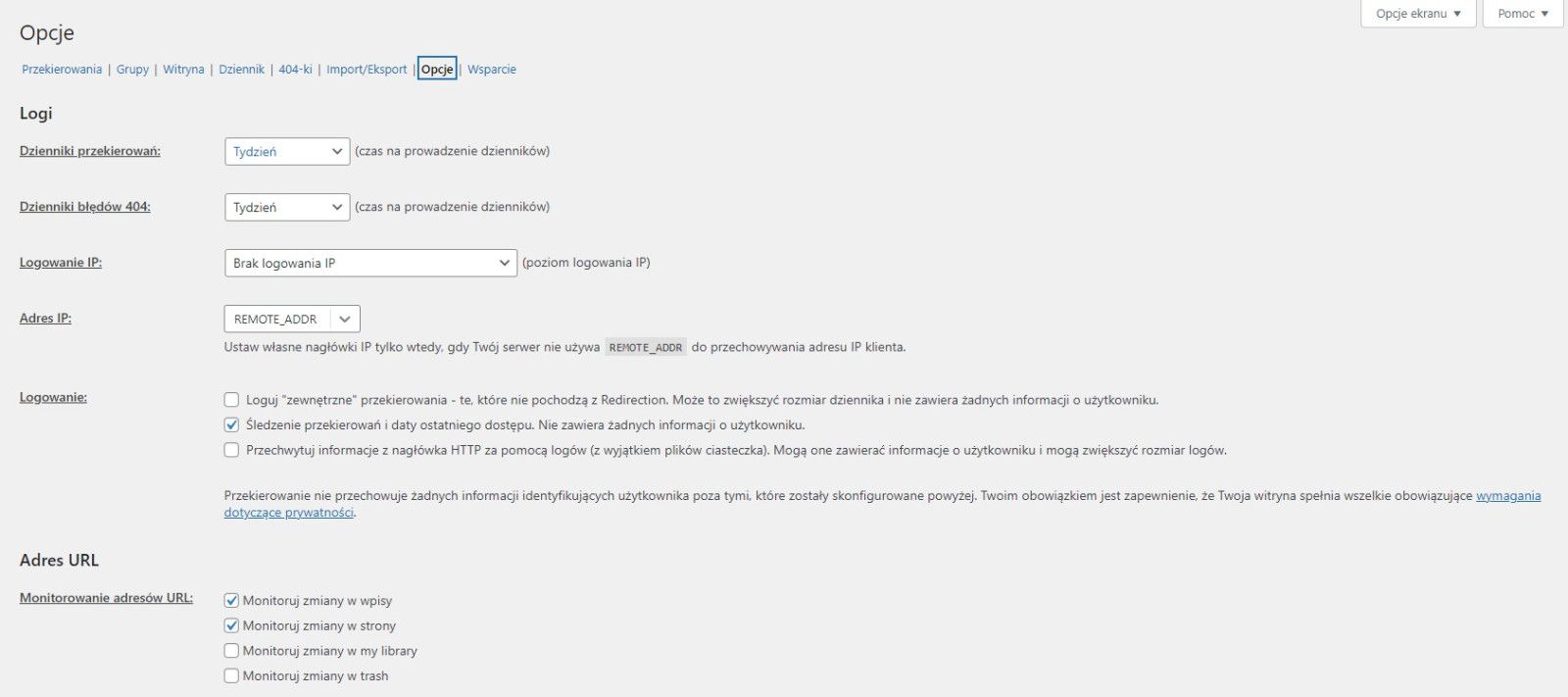
Przede wszystkim żeby zobaczyć logi, w zakładce "Opcje" musisz mieć je włączone. Domyślnie jest "Brak dzienników"; na zrzucie są ustawione na "Tydzień" (zarówno "Dzienniki przekierowań" jak i "Dzienniki błędów 404:").
Redirection nie pokazuje źródła ruchu ("referrera"), więc nie da się zobaczyć, z jakiej strony przyszedł użytkownik. Żeby odróżnić boty od realnych błędów, trzeba patrzeć na sam adres. Boty generują śmieciowe ścieżki typu /wp-login.php, /xmlrpc.php, /admin/ albo losowe ciągi znaków. Prawdziwe błędy to adresy, które wyglądają jak normalne podstrony i często powtarzają się w logu.
Szczegółowa instrukcja ustawiania adresów we Redirection
Tu uprzedzam dalsze treści, które tłumaczą jak diagnozować linki. Ponieważ jestem w sekcji o wtyczce Redirection uznałem za stosowne przykład użycia z już zdobytym adresem pokazać tutaj.
We wtyczce musisz wejść do zakładki Przekierowania i kliknąć "Dodaj nowy". Pokażą się pola do wpisywania, ale to uproszczony widok. Trzeba kliknąć w kółko zębate żeby pokazały się wszystkie pola. Po wypełnieniu wygląda to tak:
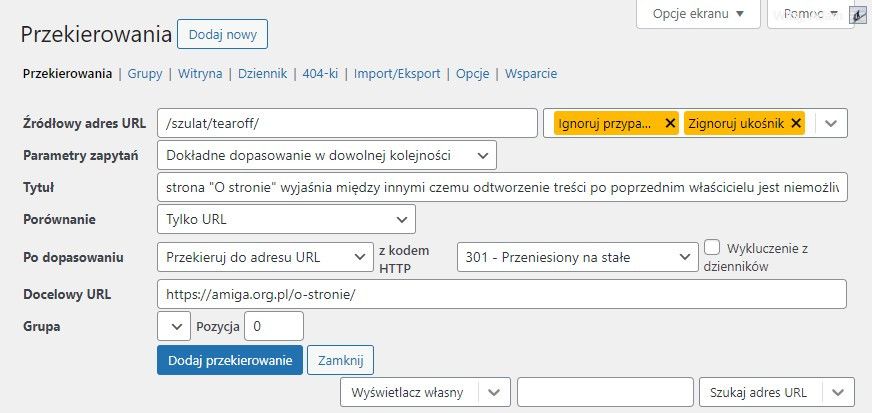
Co tu się zadziało:
- Źródłowy adres URL – tu podajesz niedziałający link bez adresu domeny
- Tytuł – to możesz ale nie musisz wpisać dlaczego robisz to przekierowanie
- Po dopasowaniu – tu wskazujesz typ dopasowanie nowego linka do starego; typy podam niżej
- Docelowy URL – tu podajesz nowy adres na jaki ma być przekierowanie złego linka, ten adres musi być już komplet łącznie z początkiem https://
- żółte przyciski – "Ignoruj przypadek" ignoruje czy są duże czy małe litery, "Zignoruj ukośnik' ignoruje czy na końcu adresu jest slash / czy nie
Typy przekierowań we wtyczce Redirection
W polu „Po dopasowaniu” wybierasz kod przekierowania z rozwijalnej listy. Dostępne opcje to głównie różne rodzaje przekierowań (kody 3xx). Najważniejszy i wystarczający w większości przypadków jest 301. Pozostałe to warianty tymczasowe lub techniczne – dla zwykłej strony rzadko potrzebne.
- 301 – Przeniesiony na stałe
Używaj zawsze, gdy stary adres ma nowy, trwały odpowiednik (np. zmiana tytułu wpisu, reorganizacja strony, migracja). Przenosi prawie całą wartość SEO na nowy adres. - 302 – Znaleziono
Tymczasowe przekierowanie. Stosuj tylko na krótki czas (np. strona w budowie na kilka dni, testy A/B, promocja sezonowa). Google nie przenosi pełnej wartości SEO. Jeśli „tymczasowe” przedłuża się ponad kilka tygodni – zmień na 301. - 303 – Zobacz inne
Specjalny przypadek po wysyłaniu formularzy (zapobiega ponownemu wysłaniu danych). Dla zwykłej strony niepotrzebny – pomiń. - 304 – Niezmodyfikowany
Nie jest przekierowaniem – informuje przeglądarkę, że strona się nie zmieniła i może użyć wersji z pamięci podręcznej. Nie ustawia się ręcznie. - 307 – Przekierowanie tymczasowe
Nowoczesna wersja 302 – zachowuje metodę żądania (np. POST). Przydatne w API lub zaawansowanych formularzach. Dla typowej strony rzadko potrzebne. - 308 – Stałe przekierowanie
Nowoczesna wersja 301 – również stałe, lepiej zachowuje metodę żądania. Google traktuje je identycznie pod względem SEO. Możesz używać zamiast 301, ale różnica jest znikoma.
Regex i wildcard – proste wyjaśnienie z życiowymi przykładami
Te dwa słowa brzmią groźnie, ale to tylko sprytne sposoby, żeby jedną regułą przekierować wiele podobnych adresów naraz. Dzięki nim nie musisz dodawać setek przekierowań ręcznie.
Wildcard – najprostszy sposób
Działa jak maska z gwiazdkami i pytajnikami.
Co oznaczają znaki?
* – dowolna ilość znaków (nawet zero)
? – dokładnie jeden znak
Kiedy to się przydaje?
Wildcard jest dobry, gdy chcesz przekierować cały katalog lub grupę adresów na jedno miejsce – najczęściej bez zachowania indywidualnych końcówek.
Przykład
Masz stary katalog /stare-artykuly/ i wszystko z niego ma iść na nową stronę działu /artykuly/.
Wpisujesz:
Źródłowy URL: /stare-artykuly/*
Docelowy URL: /artykuly/
Efekt:
/stare-artykuly/amiga-500 → /artykuly/
/stare-artykuly/amiga-1200 → /artykuly/
/stare-artykuly/cd32 → /artykuly/
Jedna reguła załatwia cały stary katalog.
Kiedy użyć ? zamiast *?
Gdy chcesz dopasować dokładnie jedną literę/cyfrę/znak.
Przykład: stare adresy to /produkt-a1, /produkt-b2, /produkt-c3 i chcesz je przekierować na /nowy/a1, /nowy/b2 itd.
Wpisujesz:
Źródłowy URL: /produkt-??
Docelowy URL: /nowy/$0 (lub po prostu /nowy/ jeśli nie zachowujesz końcówki)
?? oznacza dokładnie dwa znaki.
Regex (wyrażenie regularne) – bardziej precyzyjne
Pozwala nie tylko przekierować, ale też „złapać” fragment starego adresu i wkleić go w nowy.
Najważniejsze elementy składni (te, których najczęściej użyjesz):
^ – początek adresu
$ – koniec adresu
.+ – dowolne znaki (przynajmniej jeden)
(.+) – złap te znaki i zapamiętaj je jako $1
\d{4} – dokładnie cztery cyfry (np. rok)
* – tutaj oznacza dowolną ilość znaków (jak w wildcard)
Nawiasy łapią fragmenty, ale one są numerowane po znaku dolara - to dlatego $ zmienia się w $1. Numerowanie ($1, $2…) istnieje po to, żebyś mógł mieć kilka nawiasów i swobodnie decydować, który złapany fragment wkleić w które miejsce nowego adresu – bez tego byłaby tylko jedna możliwość wklejenia.
Przykład 1 – zmiana nazwy katalogu z zachowaniem końcówki
Stare adresy: /sklep/produkt-123, /sklep/myszka-amiga
Nowe: /nowy-sklep/produkt-123, /nowy-sklep/myszka-amiga
Wpisujesz:
Źródłowy URL: ^/sklep/(.+)$
Docelowy URL: /nowy-sklep/$1
Co się dzieje:
(.+) łapie wszystko po /sklep/ i wkleja to jako $1 w nowym adresie.
Przykład 2 – usunięcie roku z adresu
Stare: /2023/amiga-500, /2024/amiga-1200
Nowe: /amiga-500, /amiga-1200
Wpisujesz:
Źródłowy URL: ^/\d{4}/(.+)$
Docelowy URL: /$1
Różnica w stosunku do poprzedniego: \d{4} dopasowuje dokładnie cztery cyfry (rok), które są pomijane.
Przykład użycia regex do odfiltrowania śmieciowych logów
Konkretne ustawienie ma nie wyświetlać skanowania plików .php z katalogu wp-content i podkatalogach. To działalność botów i zasyfia zakładkę 404s.
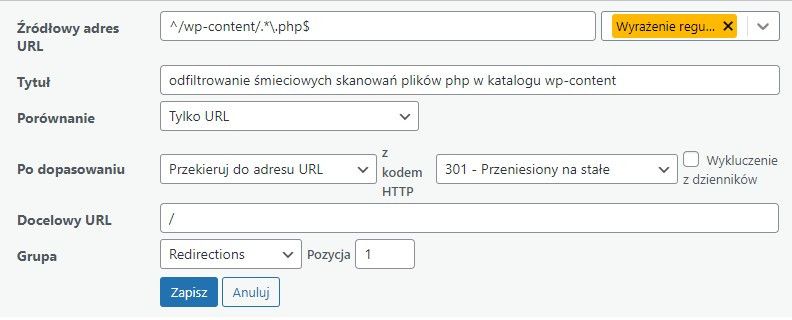
Dlaczego nie
^/wp-content/.*.php$
tylko
^/wp-content/.*\.php$
Wtyczka Redirection używa regex opartych na PCRE (Perl-Compatible Regular Expressions) w PHP, gdzie specjalne znaki jak . wymagają escapowania (\.), aby nie interpretować ich jako metaznaków. Bez tego reguła mogłaby być zbyt luźna i "łapać" żądania, których nie chcesz (np. /wp-content/something/xphp), co w skrajnym przypadku mogłoby wpływać na wydajność lub fałszywie czyścić logi z czegoś istotnego.
Żółty przycisk – musi być wybrane „Wyrażenie regularne” (bez tego wtyczka potraktuje ciąg dosłownie i reguła nic nie złapie). Poza tym będzie ci wyświetlało błąd, że nieprawidłowo zacząłeś, nie od / (a ty przecież musisz od ^).
„Po dopasowaniu” – musi być wybrane „Przekieruj do adresu URL” (np. z kodem 301 – Przeniesiony na stałe).
Dlaczego koniecznie przekierowanie, a nie „Bez przekierowania”? Opcja „Bez przekierowania” (Ignore / Nie robić nic) tylko dopasowuje URL, ale nie „przechwytuje” żądania. Żądanie nadal kończy się błędem 404 i wpis pojawia się w logach 404 wtyczki Redirection – czyli logi pozostaną zaśmiecone. Dopiero wykonanie rzeczywistego przekierowania (dowolny kod: 301, 302, 307, 410 itp.) sprawia, że Redirection uznaje żądanie za obsłużone i nie loguje go jako błąd 404. Dzięki temu śmieciowe skanowania znikają z widoku logów.
„Docelowy URL” – musi mieć coś wpisane, bo inaczej przycisk „Zapisz” pozostaje nieaktywny. Najprostsze i najbezpieczniejsze jest wpisanie samego znaku / – przekierowuje wtedy na stronę główną witryny.
Można też wpisać dowolny istniejący adres (np. /strona-glowna) lub nawet nieistniejący (np. /brak), ale / jest najwygodniejsze i nie powoduje żadnych problemów.
Dodatkowe uwagi i wskazówki:
- Kod odpowiedzi: najlepiej wybrać 410 – Gone (jeśli jest dostępny w rozwijanej liście) – informuje boty, że zasób jest trwale usunięty, co może lekko zmniejszyć liczbę dalszych skanowań. Jeśli 410 nie ma, 301 lub 302 też w pełni wystarczy do wyczyszczenia logów.
- Grupa: warto wrzucić do osobnej grupy (np. „Śmieciowe skanowania”), żeby łatwiej zarządzać takimi regułami.
- Po zapisaniu reguły logi 404 bardzo szybko przestaną się zapełniać tymi wpisami (starsze wpisy oczywiście pozostaną, ale nowe już nie).
- Jeśli zauważysz inne popularne śmieci (np. /adminer.php, /env, /wp-config.php itd.), możesz dodać kolejne podobne reguły w ten sam sposób.
Ta konfiguracja jest w 100% bezpieczna – nie wpływa na normalne działanie WordPressa, bo legalne pliki PHP nie są wywoływane bezpośrednio w /wp-content/.
Podsumowanie – kiedy co wybrać?
Wildcard – prosty i szybki, gdy cały katalog lub grupa adresów ma iść na jedno miejsce (z * lub ? dla pojedynczych znaków).
Regex – gdy chcesz zmienić strukturę, ale zachować część starego adresu (np. tytuł produktu).
W Redirection nie włączasz żadnego przycisku – wpisujesz wzorzec bezpośrednio w polu Źródłowy URL. Jeśli reguła nie działa na adresach z ukośnikiem na końcu lub bez, zaznacz żółty przycisk Zignoruj ukośnik.
Dzięki temu zamiast 100 ręcznych reguł robisz jedną lub dwie i masz spokój.
Kod 410 (adres ma zniknąć na zawsze)
W obecnej wersji wtyczki Redirection nie jest dostępny z rozwijalnej listy. Jeśli chcesz mocno zasugerować Google, że zasób usunięto trwale (szybsze wyczyszczenie indeksu), użyj innej wtyczki (np. Rank Math) lub dodaj regułę ręcznie w .htaccess. W praktyce zwykłe 404 też dobrze działa – różnica jest niewielka.
Wyłączanie rejestrowania 404
Zakładka 404s pokazuje nieobsłużone 404. To nie jest coś co powinno być stale włączone, ponieważ boty są agresywne w skanowaniu i bardzo szybko będziesz mieć kilkaset stron z ich wejściami w których ciężko cokolwiek znaleźć. Poniżej pokazuję gdzie ustawia się czas trzymania logów.
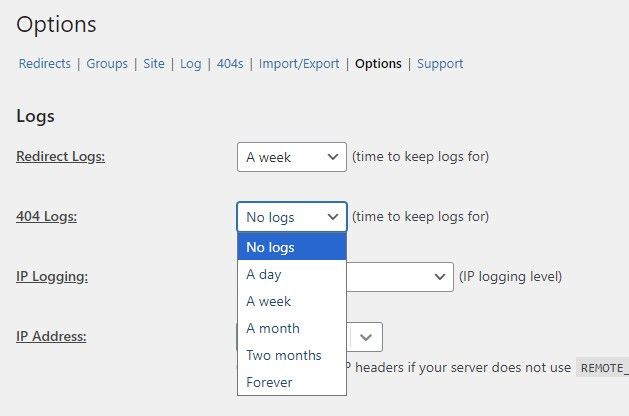
Wtyczka jest do przekierowywania i taki jest jej główny cel. Wystarczy ci obserwować trafienia (Redirect Logs). Jeśli chcesz analizować błędy 404, rób to w logach serwera lub przez zewnętrzne narzędzia – nie przez Redirection.
Co zrobić jak wtyczka nie działa
Jak widzisz zacząłem od instalacji ręcznej, przez phpMyAdmin (i tabela powstała idealnie, "na zielono"), ale panel nadal nie działał w pełni – np. grupy puste, przekierowania nie zapisywały się. Musiałem w końcu reinstalować automatycznie z repozytorium.
Okazało się, że ręczna metoda tworzy tabele, ale pomija pełną inicjalizację (hooki, JS panelu). Pokazałem ręczną, bo na tanich hostingach automatyczna często zacina się na timeoutach lub API. Ale jeśli po ręcznej nadal coś nie gra – po prostu wyłącz i usuń wtyczkę i zainstaluj jeszcze raz. Wykryje tabele i dokończy wszystko (jak u mnie w końcu ruszyło). Nic nie stracisz, a panel będzie w 100%.
Ten opis instalacji ręcznej jest wartościowy i ma sens, bo na gorszych hostingach, po nieudanej instalacji automatycznej, ręczne instalacja która tworzy tabele, zwiększa szanse na kolejne automatyczne podejście.
Pełna automatyczna aktualizacja wygląda tak:
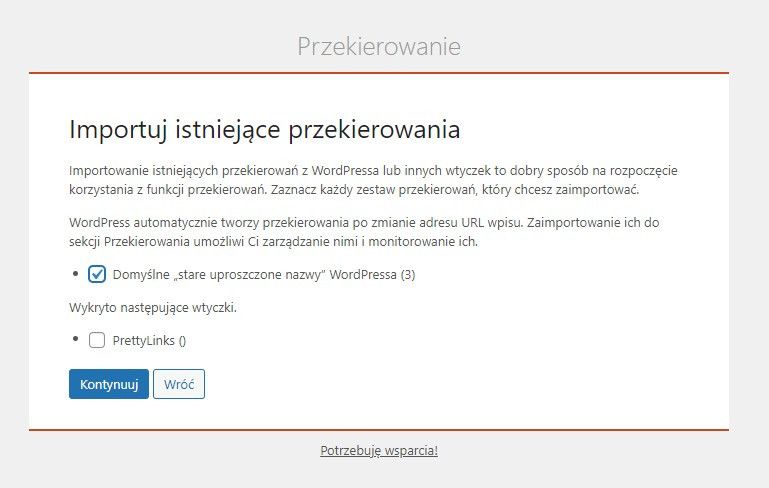
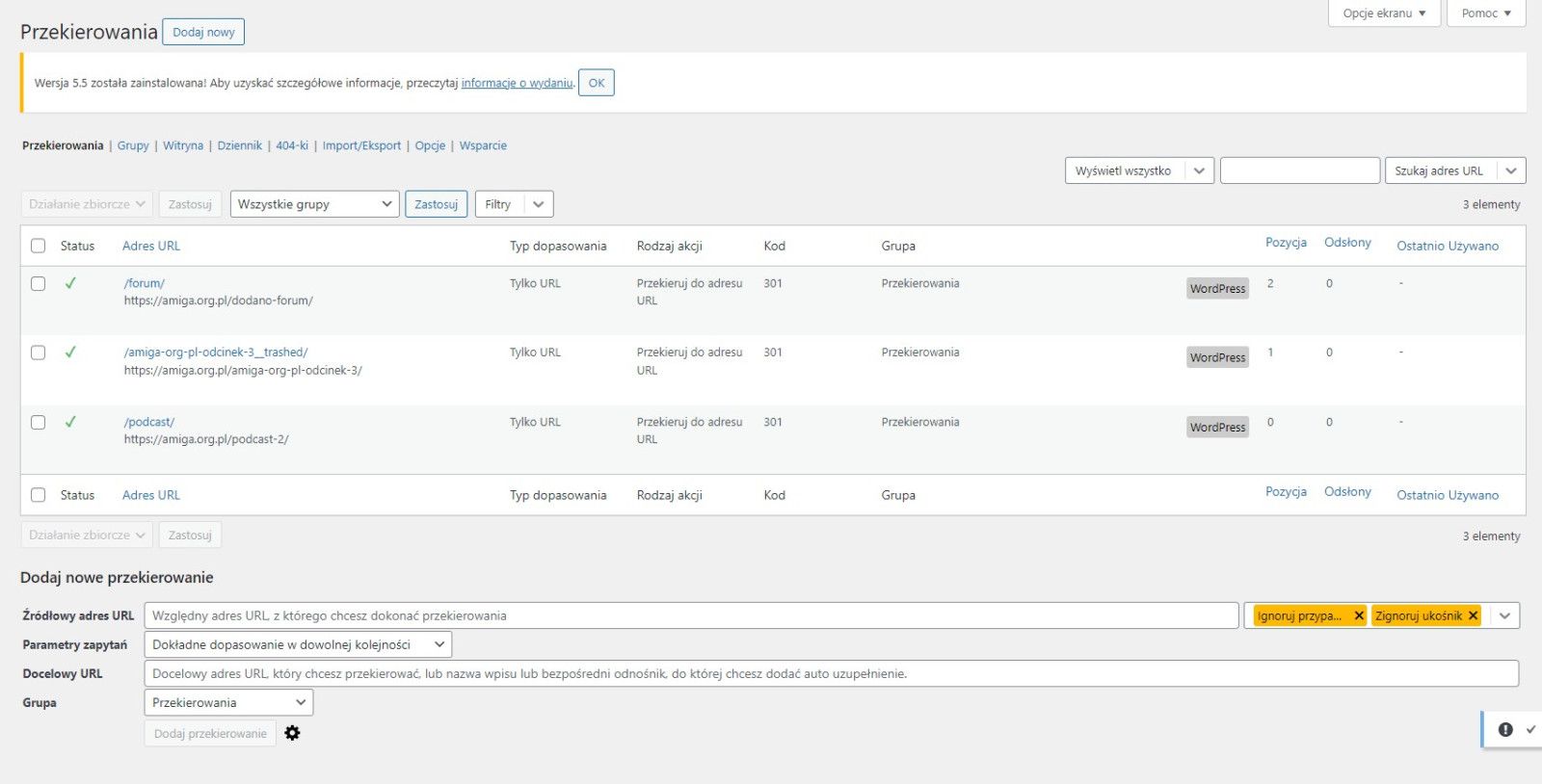
Tu już jest dobrze, widać nawet trzy zaimportowane z WordPressa przekierowania.
Na kolejnym zrzucie pokazany prawidłowo dodany adres (w dolnej części) i kompletny panel bez błędów (w górnej części, porównaj pole Grupa ze zrzutem z ręcznej instalacji).
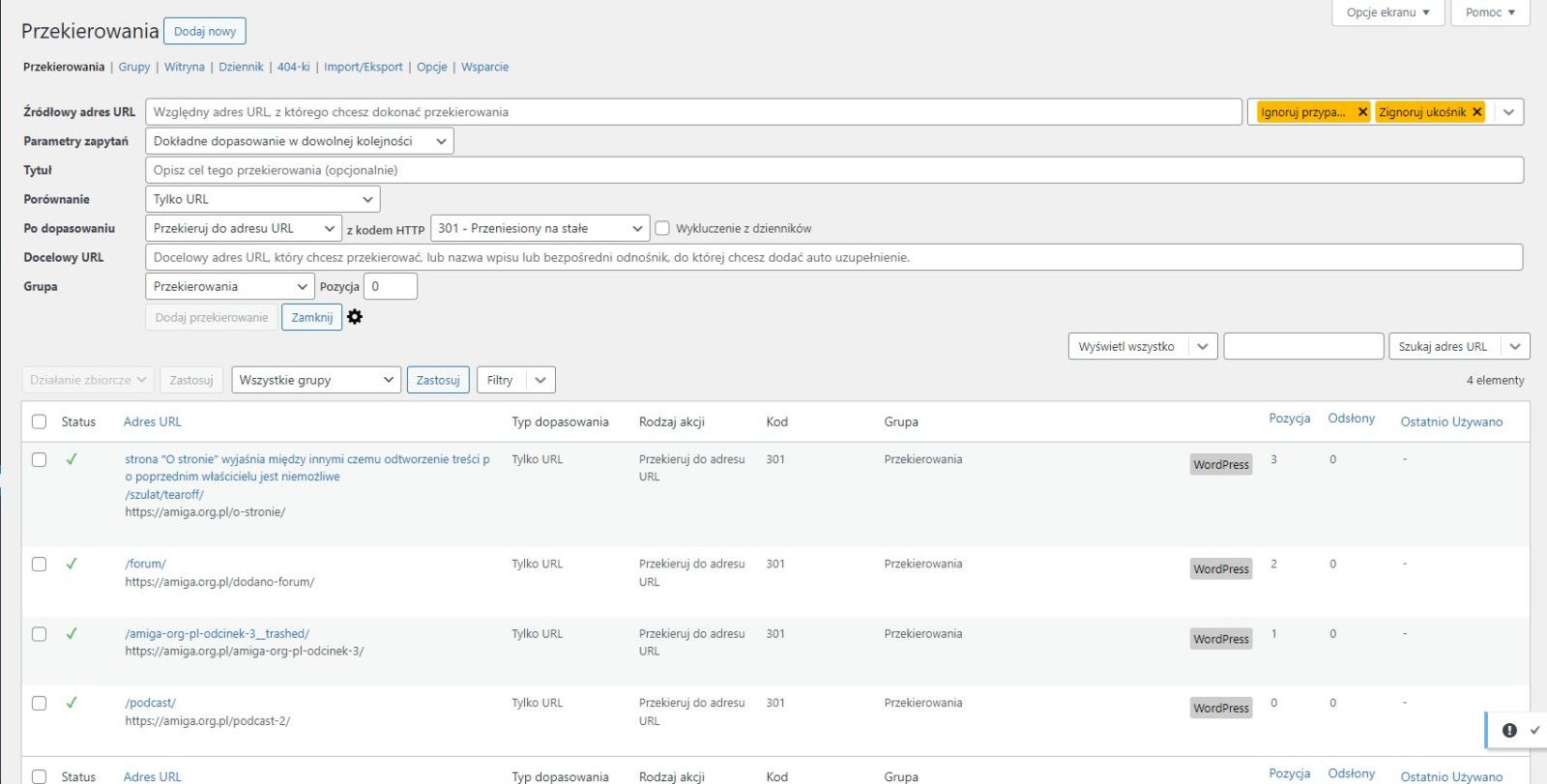
Stare adresy po poprzednim właścicielu
Ten problem pojawia się wtedy, gdy kupiłeś domenę po kimś. W Google wtedy nadal krąży masa starych adresów poprzedniego właściciela, a ludzie w to klikają, trafiając na 404.
Pojedyncze błędy 404 są normalne i nie wpływają na ranking, ale duża liczba takich adresów może obciążać crawl budget i pogarszać doświadczenie użytkownika.
Crawl budget to po prostu ilość uwagi, jaką Google poświęca na przeszukanie Twojej strony – im więcej czasu robot marnuje na błędne lub nieistniejące adresy, tym rzadziej dociera do właściwych treści.
To nie są Twoje błędy, ale to Ty musisz je posprzątać, bo Google nie wie, że strona zmieniła właściciela.
Jak to wykryć
Do tego służy Google Search Console. W panelu wybierasz zakładkę Strony i filtrujesz wyniki tak, aby pokazać adresy z błędem 404. Jeśli widzisz tam adresy, które wyglądają obco, mają inną strukturę, inne katalogi albo rozszerzenia typu .html, to są to pozostałości po poprzednim właścicielu. Przykłady:
/kontakt.html
/oferta-2017/
/galeria/zdjecia/
/produkty/abc/
Jeśli nigdy nie miałeś takich podstron, to znaczy, że Google pamięta je z dawnych lat.
Co z tym zrobić
Musisz przekierować te adresy u siebie, bo nie masz żadnego wpływu na to, co Google ma w indeksie. Wtyczka Redirection nadaje się do tego idealnie. Dla każdego starego adresu dodajesz przekierowanie na najbardziej logiczne miejsce na Twojej stronie. Jeśli nie ma żadnego sensownego odpowiednika, przekierowujesz na stronę główną. Po ustawieniu przekierowań 301 nie wykonujesz żadnej akcji w Search Console. Googlebot sam ponownie odwiedzi stare adresy i zaktualizuje raporty.
Jak to wygląda w praktyce krok po kroku
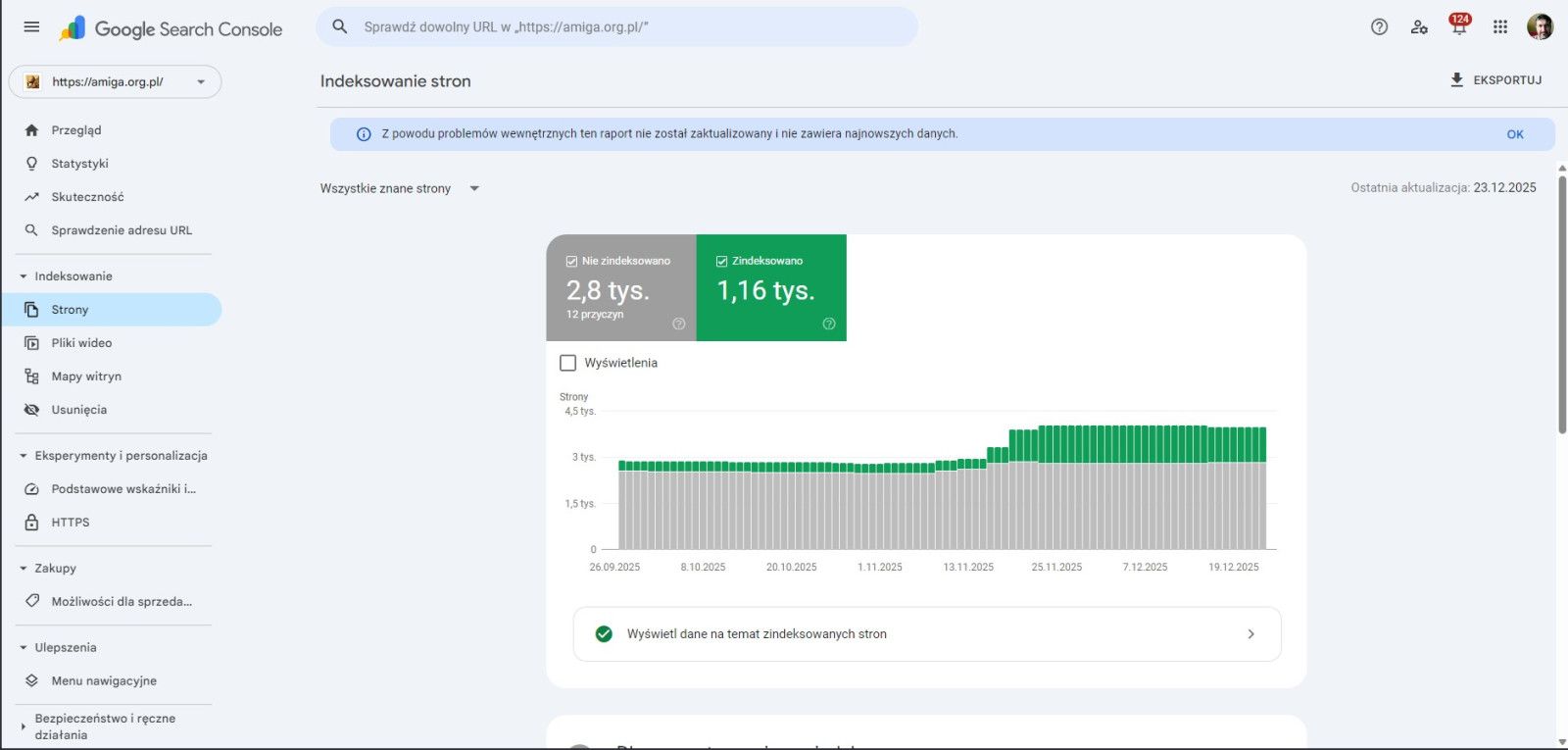
Widok powyżej to coś, co już jest skonfigurowane – miejsce wymaga zalogowania, a odpowiednia strona jest powiązana. W lewym panelu trzeba wybrać pozycję Strony, po załadowaniu jej widoczny jest wykres. Przewijając w dół trafia się na listę jak na poniższym obrazku:
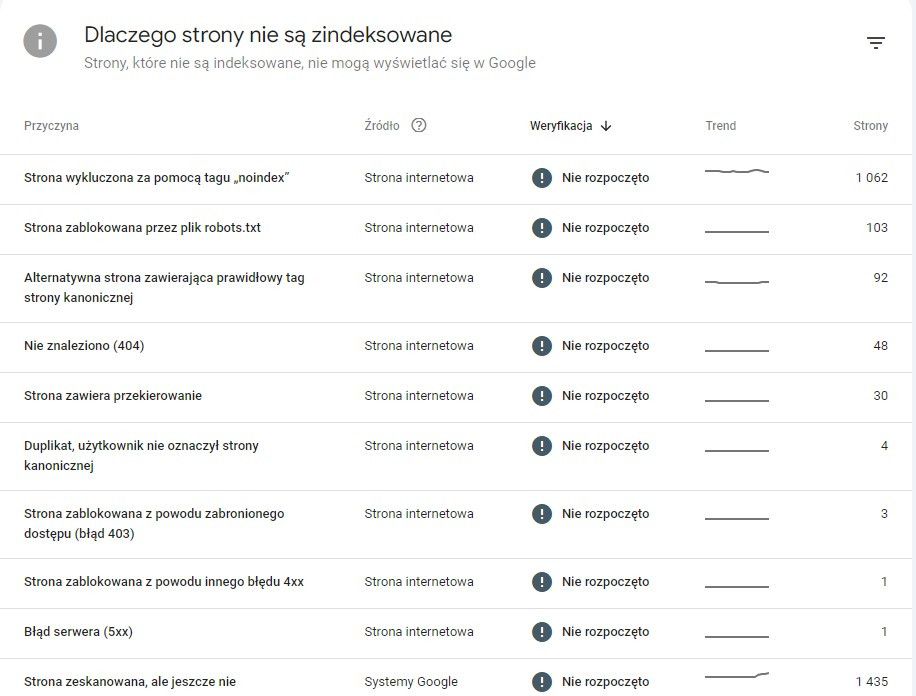
Wybierz pozycję "Nie znaleziono (404)" – klik w nią otworzy kolejną stronę z podobnym wykresem i podobnie przewiń ją w dół. Tam zobaczysz faktyczne adresy:
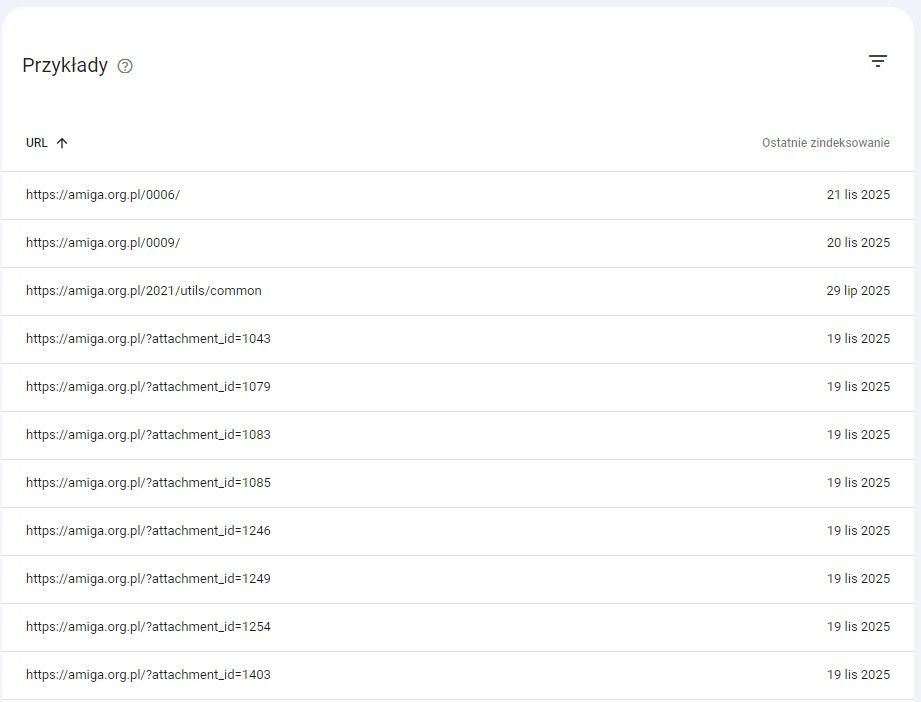
Część adresów to pozostałości po starych załącznikach – np. po zmianie motywu lub czyszczeniu miniatur WordPress może mieć ślady po dawnych plikach, które już nie istnieją. Inne adresy to linki generowane przez spam‑boty: wyglądają jak prawdziwe podstrony, ale nigdy nie istniały i Google pokazuje je tylko dlatego, że znalazł je gdzieś w internecie.
Do rzeczy – co z tymi linkami zrobić? Zależy z którymi.
Linki spam-botów – przykład: https://amiga.org.pl/rencontre-femme-algerie-avec-numero-telephone-pour-mariage/
Tym się nie zajmuj, Google samo je wyrzuci z raportu, bo to są fałszywe linki z zewnętrznych spam‑źródeł, nie Twoje treści.
Linki z parametrami udostępniania - przykład: https://amiga.org.pl/archiwalne-artykuly-online/uszy-do-gory/?share=twitter&nb=1
Możesz się tym nie zajmować, bo Google zrozumie że to ten sam adres. Albo przekierować na czysty adres, w tym przypadku byłoby to https://amiga.org.pl/archiwalne-artykuly-online/uszy-do-gory
Linki po poprzednim właścicielu domeny
Daj przekierowanie na stronę główną.
Linki wyglądające jak Twoje, ale z dziwnymi slugami
Slug to techniczne określenie obcojęzyczne. To ostatni fragment adresu URL, generowany automatycznie przez WordPressa na podstawie tytułu wpisu lub strony. To właśnie slug identyfikuje konkretną podstronę, np. /moj‑artykul/.
Jeśli slug wygląda jak normalny artykuł, ale treści nigdy nie było, to też spam. Zostawiasz 404, nic nie robisz.
Jednym zdaniem: naprawiasz tylko to, co faktycznie było Twoją treścią.
Linki z zewnętrznych serwisów prowadzące do nieistniejących podstron
To sytuacja, w której ktoś kiedyś wkleił link do Twojej strony na forum, blogu, w katalogu firm albo w artykule sponsorowanym. Ten link nadal istnieje w internecie, ale podstrona, do której prowadził, już nie. Nie masz żadnej kontroli nad tamtą stroną, więc nie możesz poprawić linku u źródła. Ruch jednak nadal do Ciebie trafia i kończy się błędem 404.
Jak to wykryć
Wtyczka Redirection zapisuje każde wejście na nieistniejący adres. Jeśli w zakładce 404s widzisz wejścia z konkretnych domen, na przykład z forów, katalogów, blogów albo portali informacyjnych, to znaczy, że ktoś linkuje do starego adresu, którego już nie masz. Adresy zwykle wyglądają znajomo, bo kiedyś istniały na Twojej stronie, ale zostały usunięte lub zmieniły nazwę.
Przykłady:
Wejście z forum prowadzi do /cennik/ który już nie istnieje
Katalog firm linkuje do /uslugi/archiwalne/
Stary artykuł sponsorowany kieruje na /produkt/abc/ którego już nie ma
Co z tym zrobić
Musisz przechwycić ten ruch u siebie. W Redirection dodajesz przekierowanie ze starego adresu na najbardziej logiczne miejsce na stronie. Jeśli istnieje aktualny odpowiednik, kierujesz tam. Jeśli nie ma żadnego sensownego miejsca, przekierowujesz na stronę główną lub kategorię, która jest najbliższa tematycznie. To jedyne rozwiązanie, bo nie masz możliwości poprawienia linku na zewnętrznej stronie.
Linki wychodzące, które masz u siebie, ale prowadzą do pustych zasobów
To sytuacja, w której link w Twoim artykule prowadzi do strony zewnętrznej, która już nie istnieje. Kiedyś działała, ale właściciel tamtej strony zmienił strukturę, usunął plik, wyłączył podstronę albo zamknął cały serwis. U Ciebie link nadal jest, ale użytkownik po kliknięciu trafia na 404 na cudzej stronie. To nie generuje błędów na Twojej stronie, ale psuje jakość treści i wiarygodność, bo czytelnik widzi, że odsyłasz do czegoś, co nie działa.
Jak to wykryć
Do tego służą narzędzia, które skanują Twoją stronę i sprawdzają, czy linki wychodzące odpowiadają poprawnie. Wynik pokazuje listę adresów, które zwracają błędy po stronie zewnętrznej, na przykład 404, 410 albo 500. Jeśli link prowadzi do zasobu, który zniknął, narzędzie to wykryje i pokaże dokładnie, w którym artykule znajduje się problem.
Przykłady:
Link do PDF-a, który został usunięty z cudzej strony
Link do artykułu, który został przeniesiony pod inny adres
Link do bloga, który wygasł i został skasowany
Link do grafiki, której już nie ma na serwerze
Co z tym zrobić
Tego nie naprawisz przekierowaniem, bo to nie jest Twój adres. Trzeba poprawić treść. Możesz usunąć link i zostawić sam tekst, podmienić go na aktualny odpowiednik, jeśli istnieje, albo dodać informację, że zasób zewnętrzny został usunięty. Jeśli materiał jest ważny, można też podlinkować wersję archiwalną, jeśli istnieje w archiwum internetowym.
Jakiego narzędzia użyć
Ja używałem wtyczki Broken Link Checker. Potem ona się zmieniła i jest w wersji Local i w wersji w chmurze (ta sama wtyczka, przy użyciu wybiera się jak chce korzystać). Wybierałem wersję lokalną, ale... Nawet wtedy bardzo obciąża serwer. Ja to miałem w pętli 72 godziny, a ponieważ ona przy obciążonym serwerze (o co łatwo przy tanim hostingu) zatrzymuje działanie, zdarzało się, że nawet te 72 godziny nie wystarczały na pełny skan. Odinstalowałem. W to miejsce polecam zewnętrzne narzędzia w postaci stron internetowych. Mają limity np. sprawdzenia 1.500 do 3.000 linków, ale często to wystarczy. Przykładowy raport poniżej.
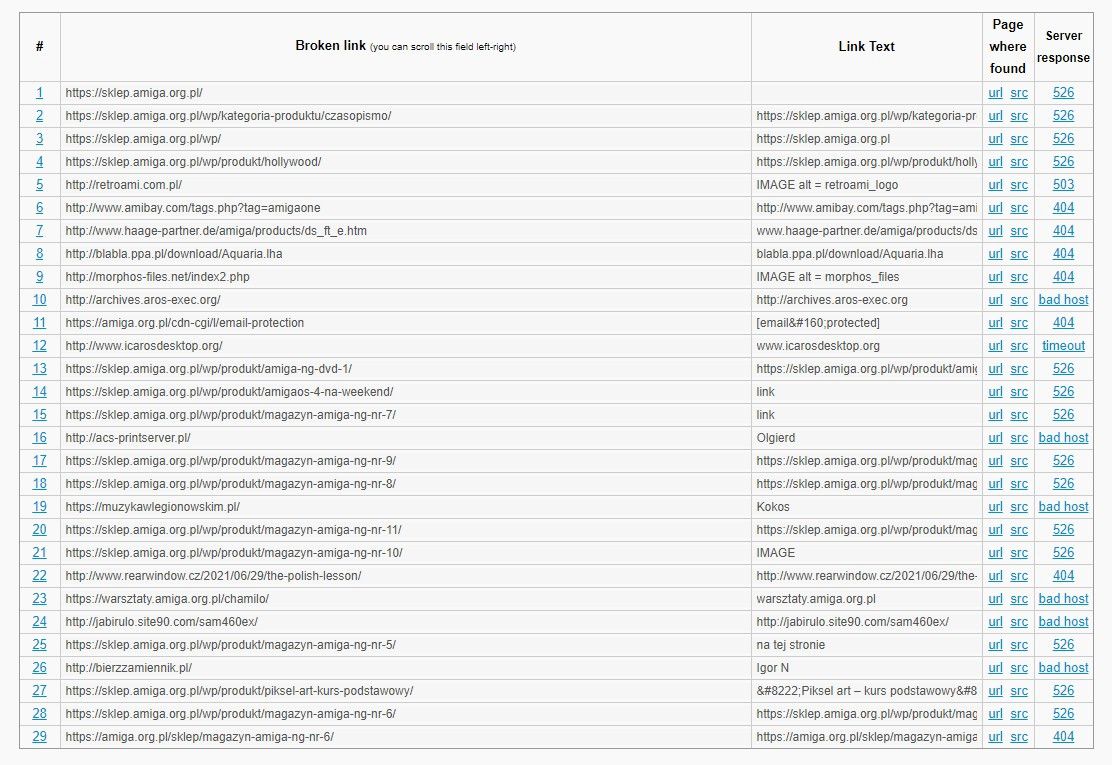
Użyte narzędzie to Free Broken Link Checker: https://www.brokenlinkcheck.com/
Jak naprawić
Spróbuj poprawić link na wersję archiwalną z Wayback Machine, jeśli jest tam kompletna zawartość. Robi to wtyczka Broken Link Checker we WordPressie w trybie lokalnym dając propozycje podmian. Ponieważ nie polecam już jej, podaję sposób "ręczny",
Przykładowy link ma schemat:
https://web.archive.org/web/*/link_do_sprawdzenia
Jeśli nie da się naprawić, poszukaj odpowiednika (może strona jest przeniesiona, a może znajdziesz odpowiednik online). Jeśli link nie da się naprawić – usuń odnośnik.
Podsumowanie
Redirection – nic nie wykrywa, tylko zapisuje próby wejścia. To nie jest narzędzie diagnostyczne. To jest miejsce, gdzie ustawiasz przekierowania i gdzie możesz podejrzeć, na jakie nieistniejące adresy ktoś próbował wejść (log 404).
Google Search Console – wykrywa to, co widzi Google. Pokazuje adresy, które Google próbował odwiedzić. Nie naprawia, nie ustawia, nie zmienia.
Broken Link Checker – wykrywa to, co masz w treści. Skanuje Twoje wpisy i strony.
Pokazuje linki, które Ty gdzieś wstawiłeś i które prowadzą do błędów.
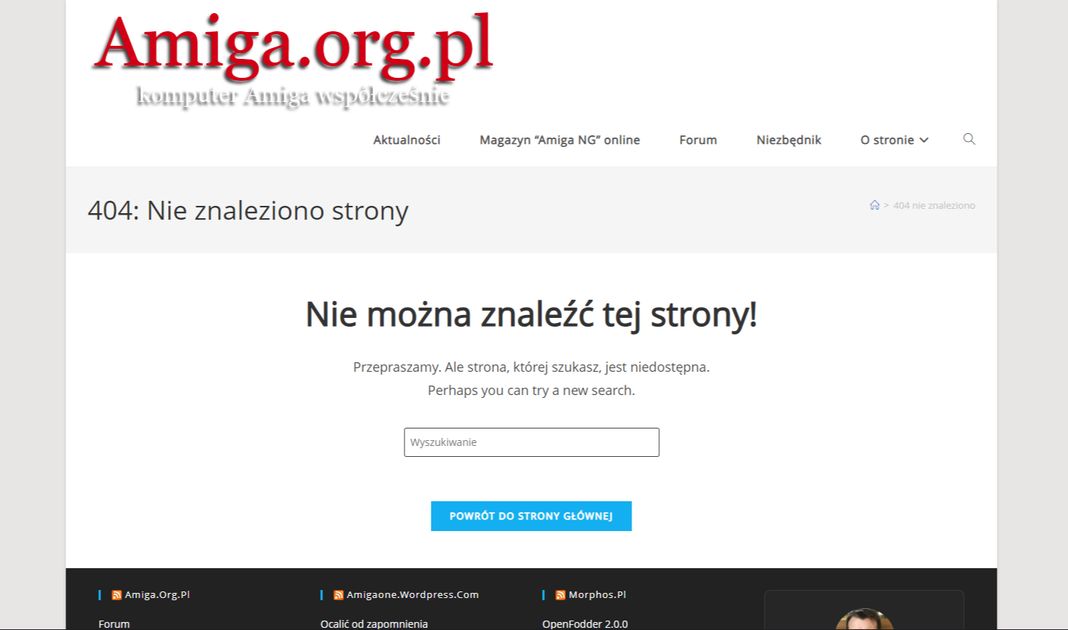
Bonus: Przyjazna strona 404 – warto ją mieć
Gdy ktoś trafi na błąd 404, nie musi od razu uciekać z Twojej strony. Dobra strona 404 powinna:
- wyraźnie informować „Strona nie istnieje” (ale miło, nie straszyć).
- zawierać wyszukiwarkę strony.
- linki do najważniejszych działów (menu główne, strona główna, popularne wpisy).
- ewentualnie humor lub grafikę (np. Amiga z komunikatem "Guru Meditation").
Jak to zrobić w WordPressie?
Najprościej zrobić to ręcznie w motywie potomnym (plik 404.php) albo wtyczką Smart Custom 404 error page (wybierasz zwykłą stronę jako szablon błędu 404 i gotowe). Wtyczkę po instalacji znajdziesz w kokpicie WordPressa w Wygląd -> 404 Error Page.
Ważne: strona musi zwracać prawdziwy kod HTTP 404 (nie 200 OK – to tzw. "soft 404", złe dla Google).
Przykład prostego tekstu na stronie 404:
„Oj, coś poszło nie tak! Szukana strona nie istnieje.
Spróbuj wyszukiwania lub wróć na stronę główną”
Zwrot "stronę główną" podlinkuj do strony głównej. Ewentualnie możesz umieścić przykładowe linki do działów strony, do najciekawszych treści albo wyszukiwarkę.
Jeśli utworzysz stronę 404 wyłącz ją z indeksowania przez wyszukiwarki.
To już naprawdę koniec
Większość poradników o 404 to clickbait, zwykła "woda" pod SEO. Ten jest po to, żebyś naprawdę rozwiązał problem, a nie tylko przeczytał ładne słówka.
 Adam Mierzwa
Adam Mierzwa


Trwa ładowanie...